Document AI Chat
Any PDF → instant knowledge base
30 sec
to answer any documentation question
2-3 days
saved per new hire on onboarding
3-5 min → sec
knowledge lookup time
The problem
Every organization has documents. Almost none of them are actually queryable. A new hire searches 400 pages of documentation for one answer. A support agent hunts through manuals while the customer waits. A developer runs Ctrl+F on a 3-year-old wiki nobody maintains.
How it works
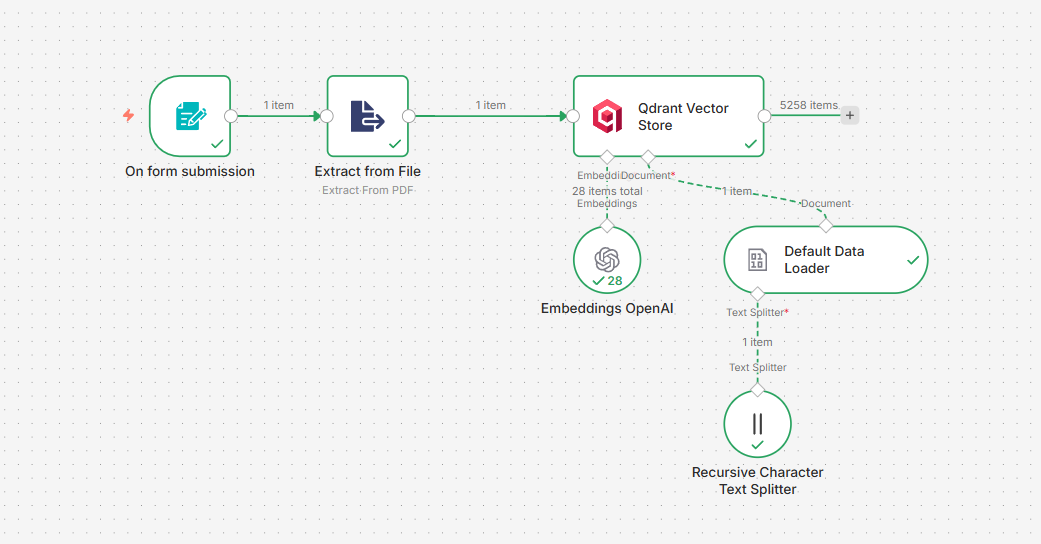
Upload a document
PDF goes through a web form — n8n extracts text, splits into 2000-char chunks with 200-char overlaps
Embedded into vectors
Each chunk becomes a 1536-dimensional vector via OpenAI Embeddings and stored in Qdrant
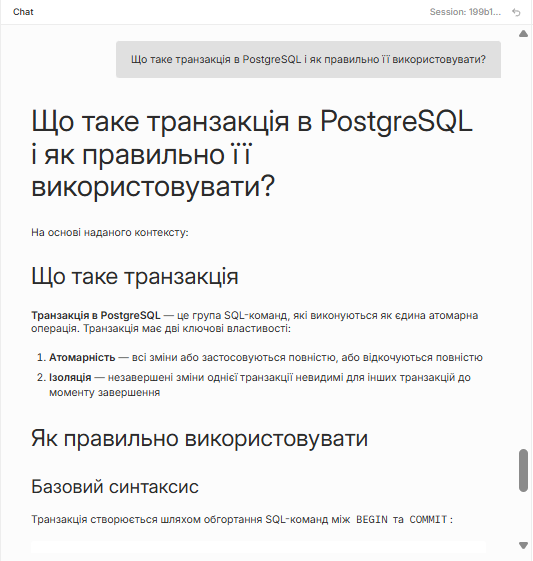
Question asked
Your question is embedded into the same vector space
Top 20 chunks retrieved
Qdrant finds the 20 most semantically similar fragments from the document
Claude reads the context
Strict prompt — answer only from the provided context, not from general knowledge
Structured answer returned
Grounded response with references. If the answer isn't in the document — Claude says so
The payoff
2-3 onboarding days saved
New hire spends days hunting answers in docs. With queryable docs: 30 seconds per question, not 30 minutes.
3-5 min → seconds per lookup
Support agents search manuals manually. Semantic search cuts that to seconds — more tickets closed, faster.
Works on any text
Tested on PostgreSQL docs (5258 chunks) and Harry Potter (366 chunks) — same semantic precision on both.
No hallucinations
Claude answers strictly from retrieved context. If the answer isn't there — it says so. No invented facts.
What's under the hood
n8n — orchestration
Two workflows: ingestion (form → PDF → Qdrant) and query (chat → search → Claude).
Qdrant — vector store
Stores 1536-dimensional embeddings with cosine similarity. Each document collection is isolated.
OpenAI Embeddings
Chunk size 2000 / overlap 200. Overlapping windows preserve context at chunk boundaries.
Claude Sonnet — the brain
Reads aggregated context and generates structured answers. Strictly grounded — no hallucinations.
Open source. Self-hostable.
Both workflow JSONs are open — import into your n8n instance, connect Qdrant and OpenAI credentials, start uploading documents.
Upload any document
Web form accepts PDF, TXT, DOC. Extraction, chunking, and embedding happen automatically.
Semantic search
Every question is embedded into a vector. Qdrant finds the 20 most semantically similar chunks.
Claude answers
Claude reads the retrieved context and answers strictly from it — no hallucinations from general knowledge.
Multilingual by default
Ask in Ukrainian, English, or any language. Claude detects and responds in the same language automatically.