AI Creative Strategy System
Raw idea → Creative Package in minutes
3-5 hrs → min
manual content strategy compressed to one run
2 QA gates
weighted scoring before and after image generation
10 stages
research → angles → scripts → images → package
The problem
Creating content for video takes 3-5 hours per piece — not because the work is hard, but because it's fragmented. Researching angles in one tab. Writing scripts in another. Generating image prompts manually. Reviewing outputs against the original brief with no automated check. Each handoff between steps loses context. The result: production-ready content is slow to ship not because of creativity, but because of coordination.
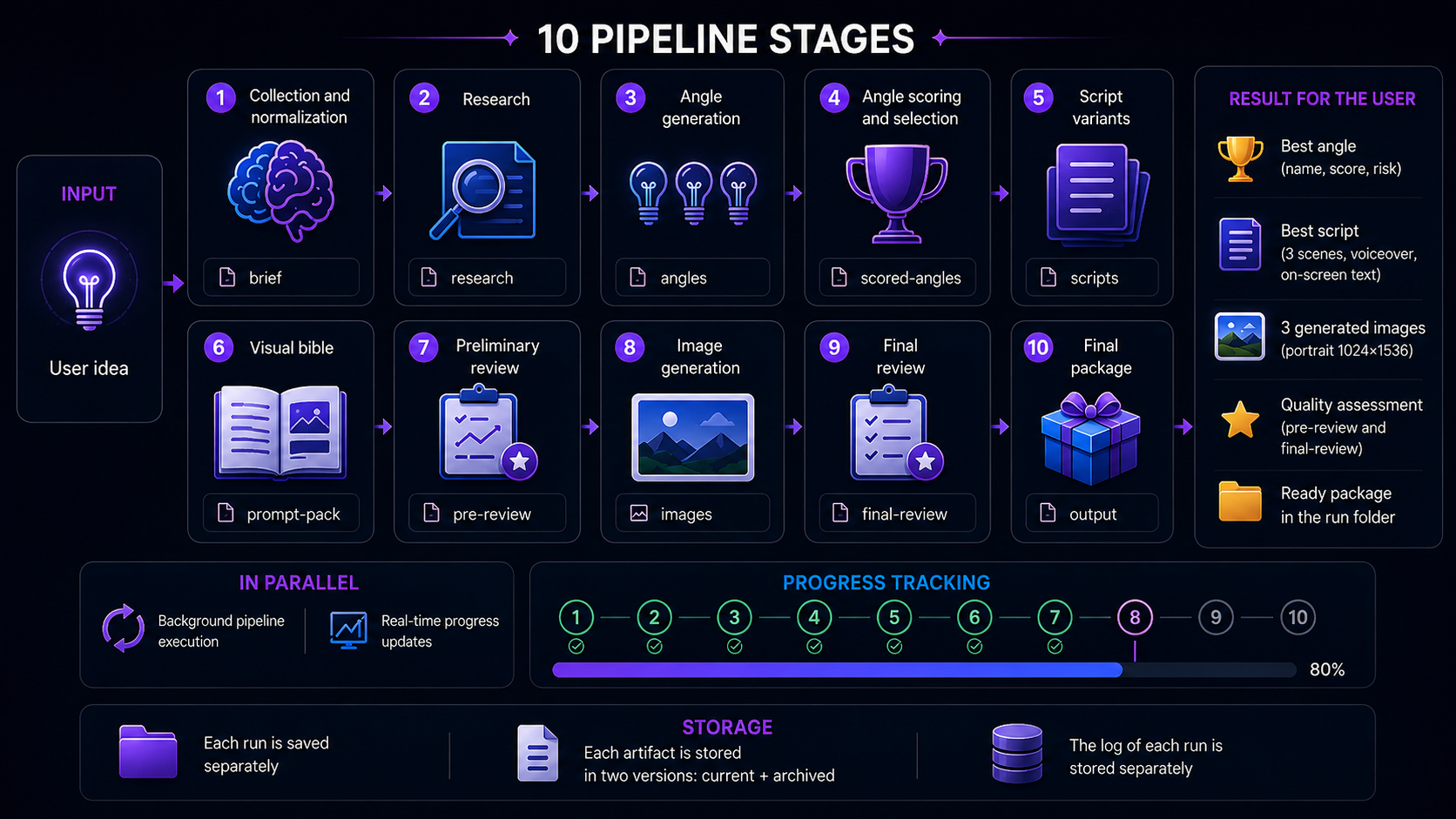
How it works
Intake
Raw idea string parsed into structured brief: topic, content format, platform, target emotion, tone
Research + Angles
Claude researches the topic and generates N content angles — each with approach, core message, and hook direction
Angle scoring
Each angle scored across virality potential, originality, and feasibility. Best angle selected for production
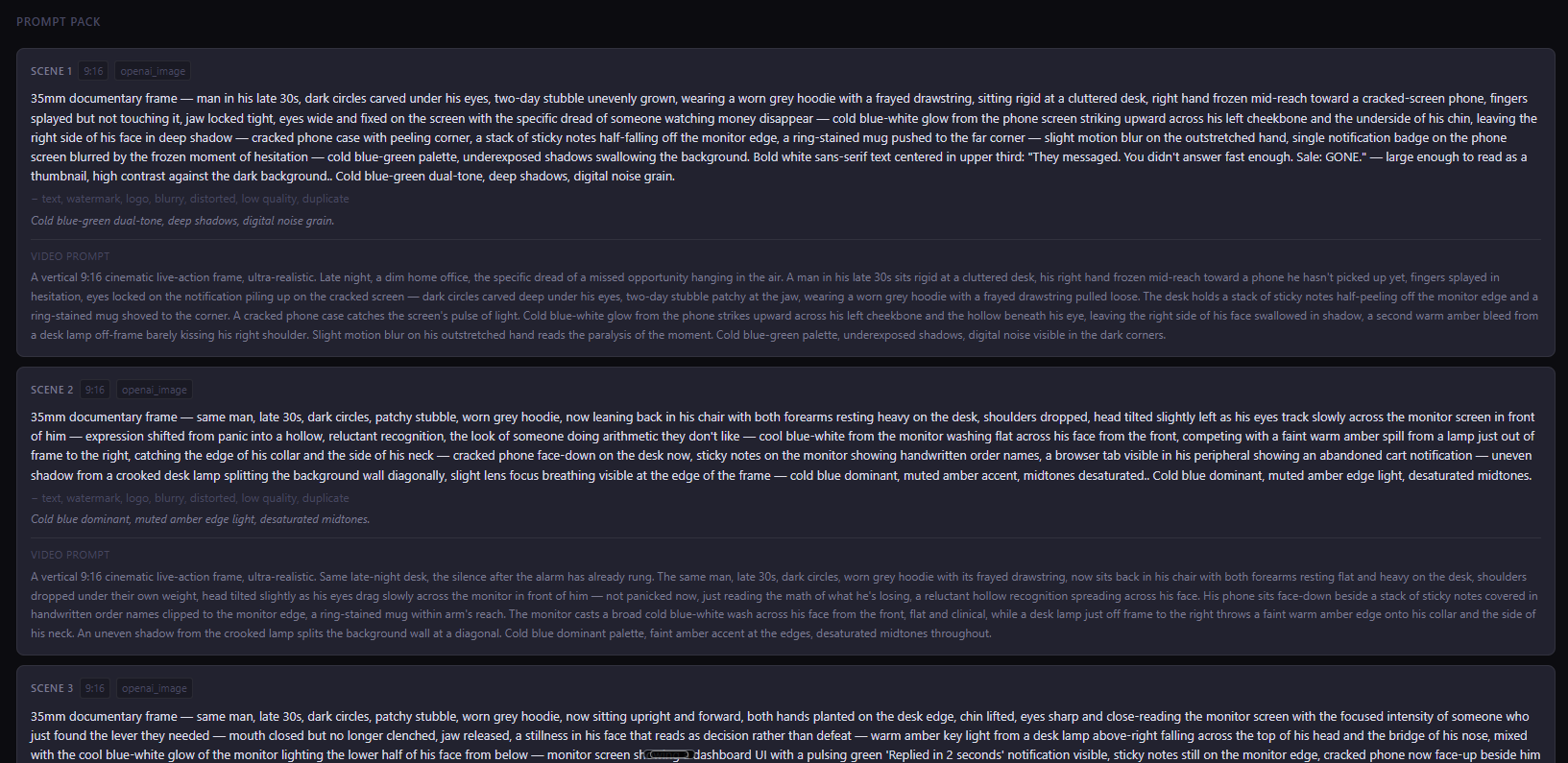
Scripts + Prompt pack
Scripts written for selected angle with scene breakdown. Image prompts built per scene with style and emotional beat
Pre-review gate
Claude scores the full package across 6 criteria (strategic fit, hook quality, script, prompts, risk, production readiness). Below threshold → revision routed to specific stage
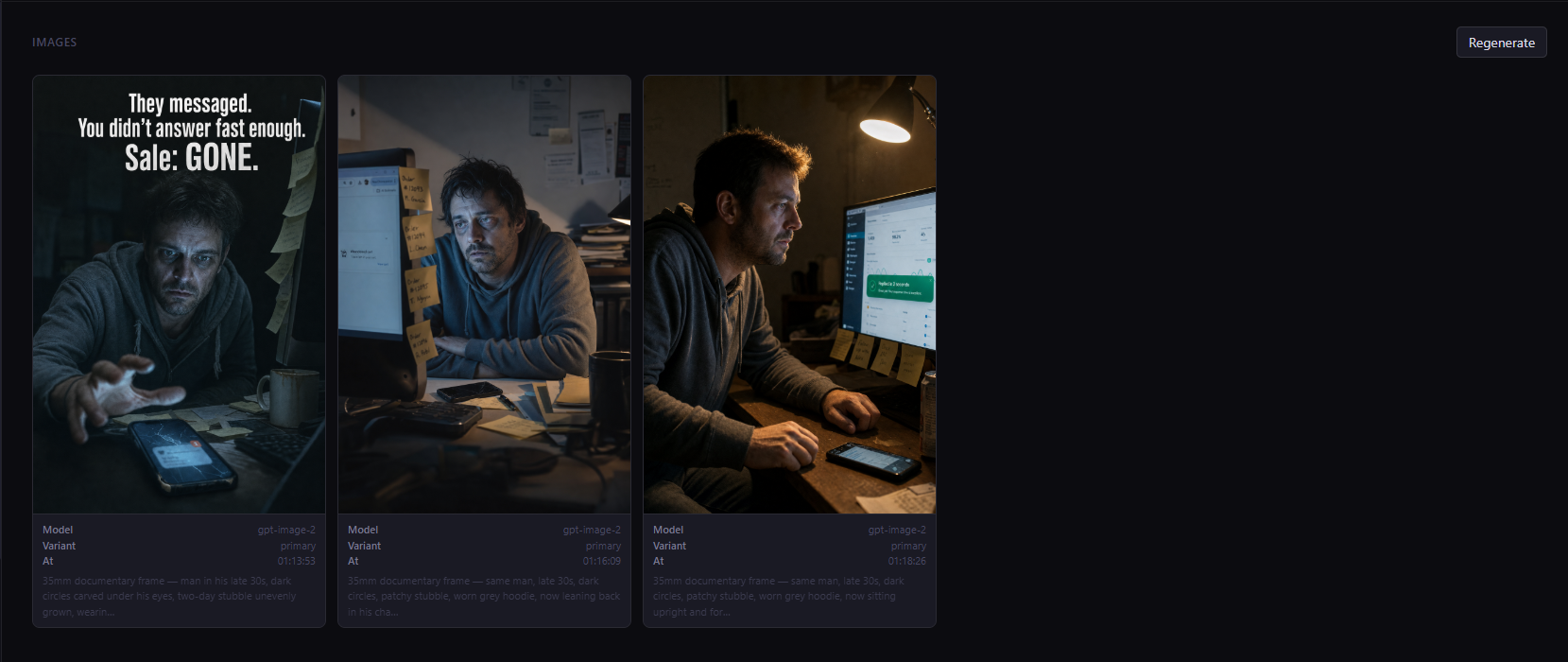
Image generation + Final review
gpt-image-2 generates scene images. Claude vision reads the actual images and scores them for emotional clarity, script match, and stock-photo risk
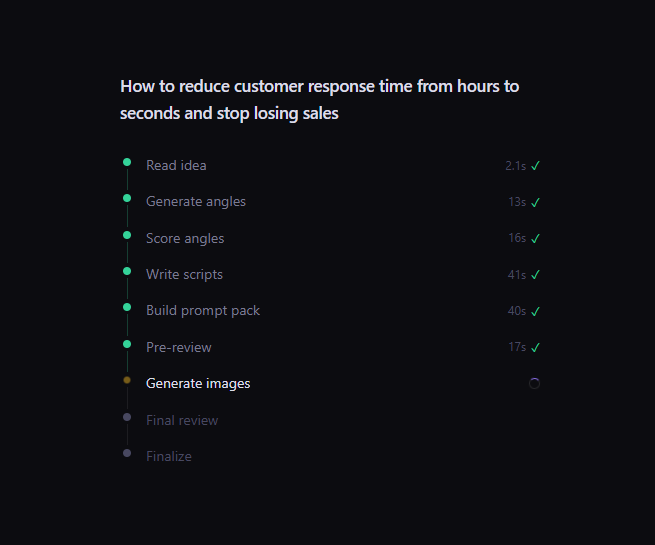
The payoff
3-5 hours → minutes
Manual content strategy per video — research, angles, script, prompts — compressed into one automated run.
Revision, not retry
Gate verdict routes directly to the stage that needs fixing. Full re-run only when strictly necessary.
Schema-validated at every stage
Broken output is caught before it propagates downstream. Fallback scoring kicks in if LLM is unavailable — no crashes.
Vision-augmented QA
Final review sends actual generated images to Claude as base64. Quality check is on pixels, not just on text descriptions.
What's under the hood
Claude Sonnet — reasoning
Handles research, angle scoring, script writing, pre-review, and final review. Strict prompts keep output schema-compatible.
OpenAI gpt-image-2 — images
Generates scene images from structured prompts. Each image tracked with status, prompt reference, and file path.
FastAPI — interface
HTTP API to submit ideas and retrieve Creative Packages. Each run gets a unique ID; artifacts versioned per run.
JSON Schema — contracts
Every stage output validated against schema. Fallback scoring computed deterministically if LLM call fails — pipeline always returns something.
Open source.
Full pipeline source available — intake to output, including schemas, prompts, and fallback logic.
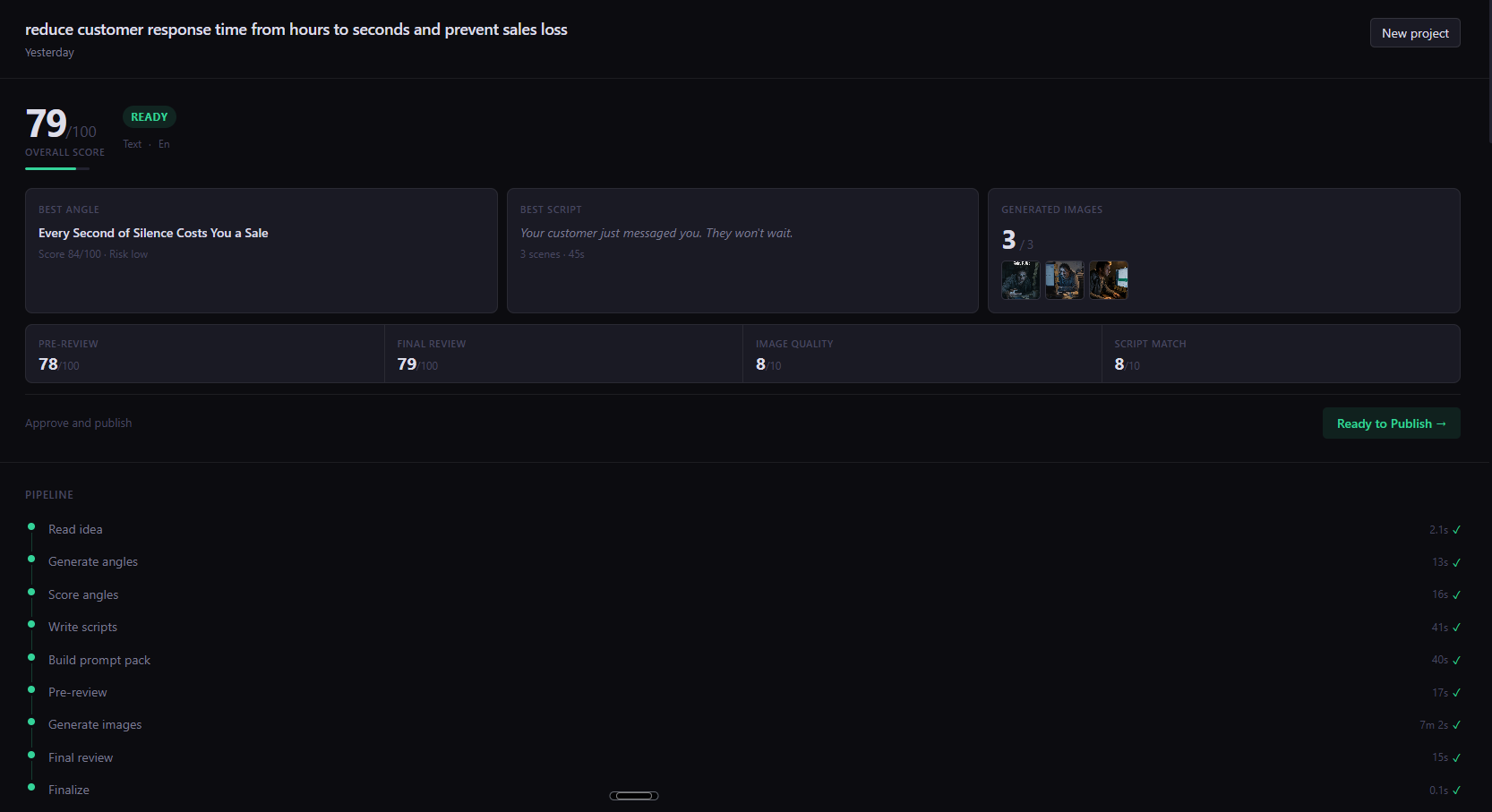
End-to-end pipeline
From raw idea to a full Creative Package with research, scripts, and AI-generated images — no manual steps in between.
2 QA gates
Pre-review scores the strategy before image generation. Final review vision-checks actual images. Both use weighted scoring — approval requires a threshold.
Deterministic revision routing
Gate verdict maps directly to the specific stage that needs fixing. No ambiguity about where a revision loop starts.
JSON Schema contracts
Every stage validates its output before passing it downstream. Schema failure routes to deterministic fallback — the pipeline never crashes.